As part of my honours project I need to query dependency graphs. A dependency graph is a directed graph where edges represent grammatical relations and nodes are tokens. I use CoreNLP and it gives a nice visualisation:

So I'm using CoreNLP, why not use tregex to query the dependency parse? Short answer I couldn't get it working for my questions. Longer answer, tregex and semgrex documentation wasn't great, I started playing around with Neo4j in a container and found it could do what I wanted. It also offered a means to persist graphs for many texts that I could query collectively at a later date.
My queries needed to extract a verb and it's arguments. Arguments need to be labelled correctly, this is dependent on the relation to the verb (or another one of it's arguments). For example, if we have the query nounPhrase verb prep nounPhrase then the prep is not linked directly to the verb but rather the second noun phrase, often the sentence object. Cypher implements an accessible syntax for expressing such patterns, this the query I used for the np v prep np pattern above:
MATCH (verb:Node)
MATCH (verb)-[rel_nsubj:REL]->(nsubj:Node)
MATCH (verb)-[rel_dobj:REL]->(dobj:Node)
MATCH (dobj)-[rel_prep:REL]->(prep:Node)
WHERE verb.part_of_speech =~ 'VB.?'
AND rel_nsubj.label = "nsubj"
AND rel_dobj.label =~ 'nmod.*'
AND rel_prep.label = "case"
RETURN nsubj, verb, prep, dobj;
(My real query is a little different to limit the verb to a set of allowed verbs)
This, Cypher syntax, is the nicest way I've seen so far to express patterns of this form. It also works well for more intricate queries such as this one:
MATCH (verb:Node)
MATCH (verb)-[rel_nsubj:REL]->(nsubj:Node)
MATCH (verb)-[rel_nmod:REL]->(nmod:Node)
MATCH (nmod)-[rel_prep:REL]->(prep:Node)
MATCH (verb2:Node)-[rel_advcl:REL]-(verb)
MATCH (verb2)-[rel_prep2:REL]-(prep2:Node)
WHERE verb.part_of_speech =~ 'VB.?'
AND rel_nsubj.label = "nsubj"
AND rel_nmod.label =~ 'nmod.*'
AND rel_prep.label = "case"
AND rel_advcl.label =~ 'advcl|ccomp'
AND verb2.part_of_speech =~ 'VB.?'
AND rel_prep2.label =~ 'mark|case'
RETURN nsubj, verb, prep, nmod, prep2, verb2;
This allows sentences like this one to be matched:

All this is in the interest of information extraction, getting these 'points' extracted correctly is a key part of my project. I'm only just starting to move onto the next step which is using the extracted information for summarization tasks. I'm specifically interested in investigating the relationships between things that people say, for example, those who talk about X are also likely to talk about Y, but not Z. Below is the kind of graph I'm working with at the moment (abortion is one of my sample debate corpora), more fine-grained summaries including information about who talks about what comes next.
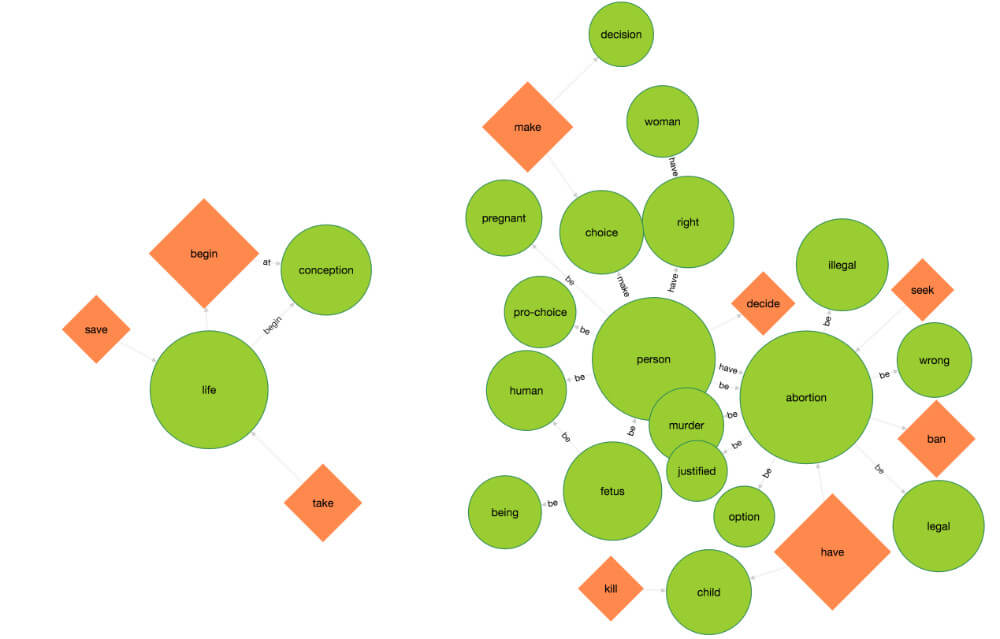 (I think this last one's quite interesting)
(I think this last one's quite interesting)