Update: The Borked demo is no longer running
Since starting work full-time I've been lacking the energy and time for side projects. Recently I've had a few free weekends and have completed initial versions of two new projects.
I've been trying to write more in the Go language as well as experimenting with new AWS products. The first project came out of a way to experiment with these. I generally like to learn new things as part of a project that does something - this time Borked was what I made.
I had the idea while I was working on charlieegan3.com. I'd introduced a few broken links as I'd migrated the site to different setups over the years. I'd scanned the site with BLS in a docker container and fixed the links. I also added HTMLProofer to my site to help stop me introducing any more.
With that completed, I was on the look out for another project. A concurrent broken link scanner seemed like a good Go starter project - BLS was quite slow. The very first version of Borked was a dead simple tool to scan sites for broken links.
I came back to it sometime later to build v2.0 - the web version. I'd learned about Go context in the meantime and was also keen to try out AWS Lambda.
 Borked v2.0
Borked v2.0
I built Borked with the eawsy Go lambda shim - behind an API Gateway. The web client is hosted on S3 and cloudfront - I'd enabled CORS on the function endpoint.
The client makes requests to the function with a root URL. The function must respond within 30 seconds when behind an API Gateway. I have it configured to return the results after 10 seconds. The function returns a list of scanned as well as incomplete links. The web client then sends subsequent requests to complete all the site's internal links - the function doesn't really have any representation of a 'job'.
Storing the progress of the scanning job on the client allows the function to be quite simple. It's not ideal but it works and seems to work reasonably quickly too.
I'd like to add some extra features to Borked - I'd like to allow for customisations like exclude patterns or User-Agent settings.
Based on the structure for Borked this weekend I was able to assemble RSSMerge pretty quickly.
 RSSMerge Homepage
RSSMerge Homepage
I've been using Feedbin as an RSS reader for about 6 months - it's got some good features but I'm really looking for a different setup. I'm no longer commuting by train and would rather have a regular roundup of my followed feeds than trying to keep up with every item in each.
Creating a merged RSS feed would allow me to get all my feeds as a single roundup email from IFTTT.
RSSMerge will take a list of RSS feeds; fetch them; interleave them in order; remove the content (leaving only the title and link) and return a new RSS feed. Feeds are again fetched concurrently so it's quite quick (even a list of about 50 feeds only takes a few seconds).
The list of feeds is passed to the API as a link to a raw Gist. This is a bit of a hack but it means that RSSMerge doesn't require any state at all. The feed URL of the RSSMerge feed is just the endpoint + raw feed list parameter. E.g.
https://rssmerge.cluster.charlieegan3.com/build?source=...
This can be used by IFTTT to create roundups like this:
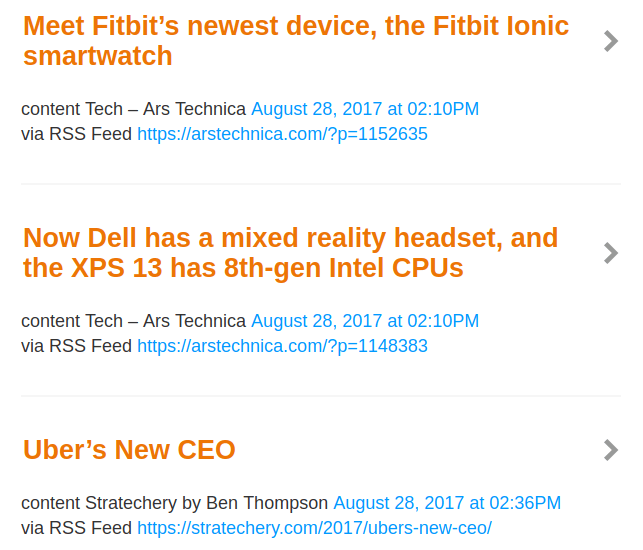 IFTTT Roundup - note multiple feed sources
IFTTT Roundup - note multiple feed sources
I have a history of not sticking to a news consumption strategy for more than a year but we'll see how this goes.
I think for my next project I'm going to make it something longer term. I might even deliberately avoid projects that could be immediately useful for me. I've found that having something I can almost use a little stressful and I'll spend too many late nights trying to get it working. I'm not sure that's particularly healthy or productive. Having a project that that was more complicated and longer term might help keep things more manageable while being a more valuable learning experience.