I enjoy using Instagram to share my photos. The restricted feature-set; public-by-default; similarities to Twitter & (original) square format constraint all appeal.
Last year I completed a #365photochallenge on Instagram. Over the year, this took quite a lot of effort. As I switched to posting photos on the day they were taken it became clear to me that this was a valuable record of my activities for years to come.
This prompted me to find a way to extract a copy of the data I was creating and managing via Instagram. It turns out this is surprisingly hard.
I originally started using Zapier/IFTTT to save photos, as they were taken, into my Dropbox. Sadly, these services stopped saving the full-res images and sometimes missed posts(?). This also only saved new images - really I wanted my entire catalogue including all images and metadata.
I tried using Airtable and Zapier for the metadata but found the Zapier free tier too limited and their plans too expensive. This also only worked new posts.
I tried various Instagram media downloader extensions for Chrome; these save the images but not the data. I also wanted the process to be largely automated which this wasn't.
I found a project called InstaLooter and opted to use that when I saw it was also able to save json post data.
This is the process: first, download the json post data in instaLooter to a
looted_json folder.
instaLooter USERNAME looted_json -v -D -T {date}-{id} --new --time thisyear
# or in docker
docker run -v "$(pwd)/looted_json:/out" -it python:alpine3.6 sh -c "pip install instaLooter && ls /out && instaLooter USERNAME /out -v -D -T {date}-{id} --new --time thisyear"
Next, fill out the data by visiting each post's public page. Save the completed
data in completed_json.
#!/usr/bin/env ruby
require "json"
require "date"
require "open-uri"
Dir.glob("looted_json/*").shuffle.map do |file|
completed_file_name = "completed_json/#{file.split("/").last}"
next if File.exists?(completed_file_name)
puts file
raw_data = JSON.parse(File.read(file))
doc = open("https://www.instagram.com/p/#{raw_data["code"]}").read
page_data = doc.scan(/\{[^\n]+\}/).map { |r| JSON.parse(r) rescue nil }.compact.first
graph_image = page_data.dig(*%w(entry_data PostPage)).first.dig(*%w(graphql shortcode_media))
caption = graph_image["edge_media_to_caption"]["edges"].first["node"]["text"] rescue ""
tags = caption.scan(/#\w+/).uniq
completed_data = {
id: raw_data["id"],
code: raw_data["code"],
display_url: graph_image["display_url"],
media_url: raw_data["is_video"] ? graph_image["video_url"] : graph_image["display_url"],
post_url: "https://www.instagram.com/p/#{raw_data["code"]}",
is_video: raw_data["is_video"] == true,
caption: caption,
location: graph_image["location"],
tags: tags,
timestamp: raw_data["date"],
dimensions: raw_data["dimensions"]
}
File.write(completed_file_name, JSON.pretty_generate(completed_data))
end
I have an optional step here to download the location data. Using the location
data from each post, I can get a list of all the locations used and visit each
page on the Instagram site to get it's coordinates. All the locations are saved
as their own json file in a locations folder.
#!/usr/bin/env ruby
require "json"
require "open-uri"
Dir.glob("completed_json/*").map do |file|
JSON.parse(File.read(file))["location"]
end.uniq.compact.each do |location|
puts location["name"]
location_file_name = "locations/#{location["id"]}.json"
next if File.exists?(location_file_name)
html = open("https://www.instagram.com/explore/locations/#{location["id"]}").read
page_data = html.scan(/\{[^\n]+\}/).map { |r| JSON.parse(r) rescue nil }.compact.first
location_data = page_data.dig(*%w(entry_data LocationsPage)).first["location"]
location.merge!(lat: location_data["lat"], long: location_data["lng"])
location.delete("has_public_page")
File.write(location_file_name, JSON.pretty_generate(location))
end
Finally, all that's left to download is the media files (images and videos).
Luckily, we have all the information we need in our completed_json files.
#!/usr/bin/env ruby
require "json"
require "open-uri"
require "fileutils"
Dir.glob("completed_json/*").shuffle.map do |file|
data = JSON.parse(File.read(file))
format = data["is_video"] == true ? "mp4" : "jpg"
media_file_name = "media/#{file.split("/").last.gsub("json", format)}"
next if File.exists?(media_file_name)
puts data["post_url"]
begin
File.write(media_file_name, open(data["media_url"]).read)
FileUtils.touch media_file_name, mtime: data["timestamp"]
rescue
puts "#{media_file_name} Failed"
File.delete(media_file_name) if File.exists?(media_file_name)
end
end
Now you'll also have a media folder with all media in!
The 'posting experience' on Instagram is the most satisfying I've found, it's just a shame it's such a pain to get your data out. I'd really love to see a "Download my Instagram Archive" feature like Twitter has.
Having access to the raw data is really fun. I was able to make a calendar for Mum this Christmas for example. When I added the location data download I also brought back a (rudimentary) version of the discontinued Instagram photo map.
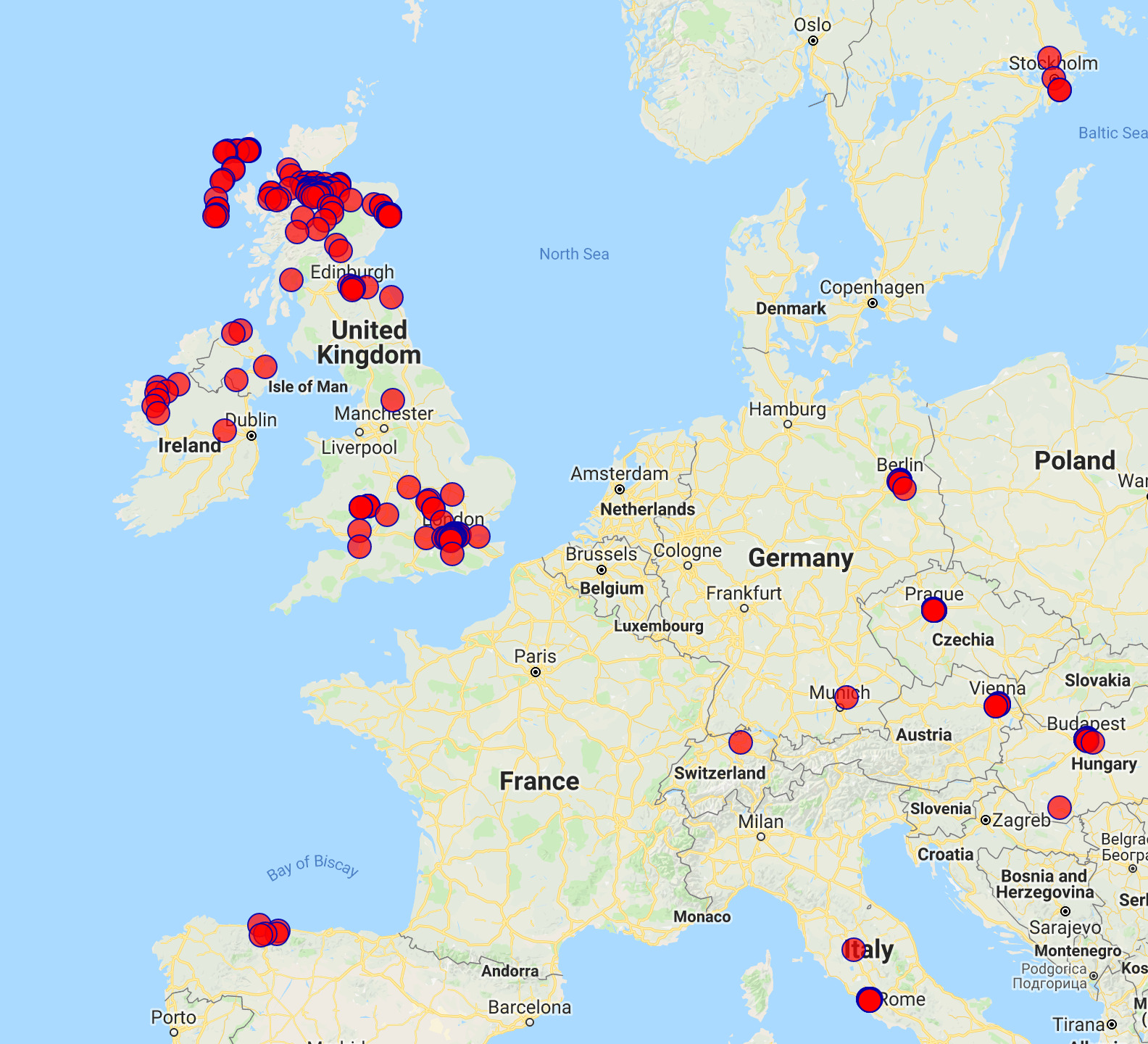
This features all the countries I've been to (didn't go abroad before getting my Instagram account). I wonder what this will look like after a few more years...
I do worry about depending on Instagram as a means of personal archive in this way. However, I feel like now I have this format for extracting my data, that I have some portability to continue this elsewhere if Instagram stops working for me.